

By Beth Hughes, Esq., eDiscovery Project Manager
Protecting sensitive and personal data is mission-critical to many organizations. Companies should strive to take all reasonable measures to keep organizational, client and customer data safe from security threats. If you have concerns about mitigating the risk of cyberattacks, bit-x-bit’s team of experts would be happy to help. But what do you do if, despite best efforts, a security incident has occurred and you have concerns that the threat actor accessed sensitive data, e.g., personally identifiable information (“PII”) or protected health information (“PHI”)?
Beyond informing key internal stakeholders, there are a patchwork of industry-specific federal requirements, such as HIPAA, as well as state-level mandates requiring organizations to notify certain third parties (e.g., customers, patients, business partners) if the incident rises to the level of a breach. There are also potentially international requirements to consider, such as the European Union’s General Data Protection Regulation (GDPR), if the company stores data for EU citizens. This all means a company may ultimately be sending notices to impacted individuals and to various state, federal or foreign government agencies — perhaps on a rolling basis — in order to meet these varying requirements. Your attorney can advise you on the specific requirements for these notifications.
How can an organization swiftly but thoroughly identify the relevant sensitive information in an effort to meet its various notification obligations? As you might imagine, the requisite steps will depend on the type of data that was accessed and where the impacted individuals reside. Your legal team would need to quickly assess which custodians were impacted, where they worked, and what roles they hold at the organization. From a technical perspective, after determining how and when the breach occurred, and remediating the security vulnerabilities, the next step often involves identifying the sensitive data that was accessed. This is where our expertise and use of analytics technology frequently used on eDiscovery matters comes into play.
Once the relevant data has been identified and collected, we use advanced analytics tools to help isolate the potential PII/PHI, which helps the organization (and its counsel) design a plan for reviewing and ultimately identifying the PII that must be assessed. For example, perhaps the exposed data was from a Human Resources employee who received applications of potential employees and had access to employee files. This person likely has more PII in their day-to-day user-generated documents than a field sales representative. You may need a larger team to review these documents, as they may be richer in PII, and it will be wise to start assembling that team as soon as possible.
Once the data has been identified and collected, it can then be processed using eDiscovery processing tools. This will extract the individual files from their containers (e.g. pulling office documents from zip files and emails and attachments from containers such as PST or OST files), and also extract the text. For files without searchable text (such as non-searchable PDF and TIF images), we use optical character recognition (OCR) to create searchable text. This is particularly useful for files such as scanned tax forms and signed agreements and applications. After that is complete, we can de-duplicate the documents and complete email-threading. This helps reduce duplicative review – negating the need to review the same document twice. This does not affect any reporting of what data might have been exposed, merely what data might require human review.
Once we have our fully processed, de-duplicated dataset, our experts utilize analytics tools to assist in identifying PII, such as Social Security numbers, credit card numbers, driver’s license information, account numbers, birth dates, and medical information, etc. These tools can help us bucket the set into the documents that are more (and less) likely to contain these types of PII, as well as specifically which types. This can help further refine the review plan.
To facilitate the review process, we developed a custom add-on tool for Relativity to catalog the impacted individuals and their exposed PII. We have seen teams try to create their notification lists using methods such as Excel. This can get unwieldy fast, especially with large teams creating duplicate entries. With our custom-built solution, we can create a record that contains all of the data associated with each individual. Akin to a file in a filing cabinet, we create a file as we find a new individual, and can add whatever exposed PII we find to that individual’s file (e.g. Social Security number, account number, date of birth, etc.) as we find it. Because each file is updated in real time, the reviewers won’t create duplicate entries, as is often the case (from our experience) when review teams use an Excel spreadsheet to manually create individual lists. We can also add the individual’s state of residence if it is found in the dataset, and link to the documents in which information was found. This greatly increases efficiency and assists in keeping duplication at bay. Also, if we need to see the documents for any affected individual at any point, we can pull them up quickly.
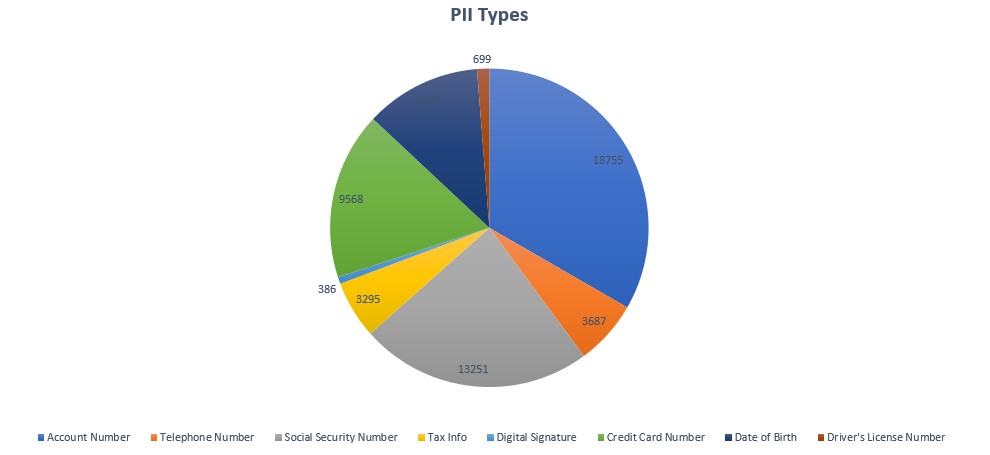
Once review is complete (or at any point along the way, if rolling reports are necessary), our customized tool can provide a report containing any of the necessary information for notification purposes. In this way, we help reduce the time spent identifying the necessary information to be reported. When sensitive data has been breached, time is what matters most.