

By Abbye Needham, Esq., eDiscovery Services Manager
H5 Matter Analytics (“H5MA”) is a Relativity integrated application that uses advanced data analytic algorithms to streamline electronic document review by dramatically reducing the number of documents the team needs to review, resulting in the defensible saving of time and money. H5MA’s analytics enable rapid sorting through mountains of data and generates helpful and informative data visualization charts. This blog will discuss three of those analytics functions: email threading, Text Duplicate Identification and Metadata Augmentation.
As data sizes grow it is imperative to have an analytics toolbelt that can help clients navigate the data, reduce the size and find the relevant documents faster. H5MA’s email threading feature provides dramatic data insights. H5MA’s email threading allows users to view detail reports which break down the number of inclusive emails as well as items such as file type, custodian and date range of the data set.

It also runs name normalization during threading, which allows clients to see all the different email accounts for a specific person inside their data set.

These reports are available inside of Relativity. Permissions can be granted to specific user groups for viewing inside the Relativity platform, or they can be exported and delivered via email.
Another benefit of H5MA’s email threading is the email thread viewer. The viewer allows users to visualize the email thread and see where the email falls in the chain. You can also see the reason for each most inclusive email in each chain. This integrated viewer simplifies email threading and gives you an additional way to visualize your data set. An example follows:
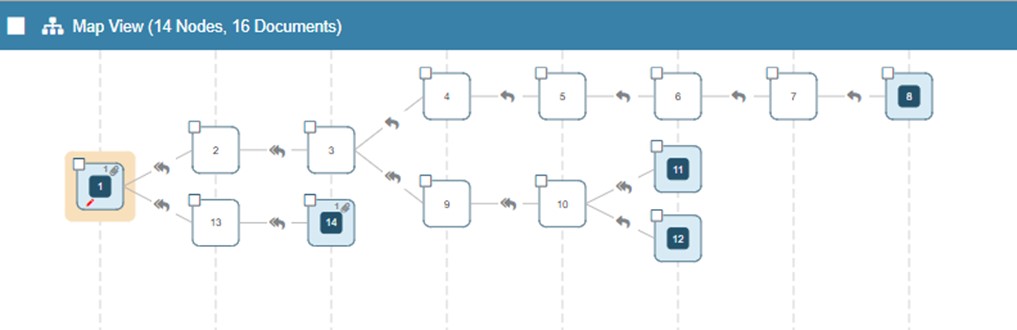
In the foregoing “Map View” of an email chain, Box 1, 14, 11, 12 and 8 are all identified as Most Inclusive Emails. Box 1 is considered most inclusive as it contains an attachment that none of the other emails in the chain contain, the other Boxes highlighted in blue (14, 11, 12, and 8) are the respective ends of a chain that broke off from the email thread. When you hover over any of the boxes, you will receive information as to why an email is Most Inclusive as well as the From, Sent date and number of participants for each email.
In our experience we have seen that utilizing H5MA’s email threading can further reduce a search term culled review population by up to 30%. The reduction will depend on the number of emails and email chain in the analyzed set; however, even on smaller cases we have seen H5MA reduce the email population by up to 15%, which certainly saves the client time and money. The ability to load a culled set for review, and then further reduce that set by batching only most inclusive documents with families, is a huge time-saver and can result in a dramatic reduction in the cost of a review team.
H5 Matter Analytics also offers additional algorithms or features, such as Metadata Augmentation, Near Duplicate and Textual Duplicate identification, and Personal Identifiable Information (PII) identification. Metadata Augmentation allows you to analyze the text of documents to supplement metadata received for the documents. For example, you can run the Metadata Remediation algorithm across data without metadata and use the text to populate the following fields: Email From, Email To, Email CC, Email BCC, Email Subject and Sent Date. Near Duplicate and Textual Duplicate identification uses the extracted text of your data set to identify 100% duplicates based on text and/or documents that are similar to other documents based on text. Textual duplicate identification allows you to compare data sets from different sources, e.g. an opposing party production and processed data, and locate duplicate documents that are duplicates based on text but may not be duplicative based on the MD5 Hash. Near duplicate identification identifies documents that are a specific percentage similar to other documents which can aide in streamlining review and allowing you to see additions/subtractions on different versions of a draft document. PII Identification uses regular expression algorithms to identify documents likely to include categories of highly confidential information, such as financial data, date of birth, social security numbers, medical information, etc. These additional features allow users to further digest their data, streamline review and gain valuable insights into their data sets. H5MA provides reports on every feature and you can focus the algorithms on a specific saved search to target a specific data set or the entire database.
At bit-x-bit, we have seen the value of using H5MA Metadata Augmentation firsthand. In one matter, we used the Metadata Augmentation to populate metadata fields that were not provided in an opposing party production. H5MA was quickly able to analyze a set of 10,124 emails and attachments and pull out the From, To, CC, Subject and Sent Date for 5,370 emails. All of this metadata was missing from the production deliverable.
In summary, our eDiscovery Group members at bit-x-bit are strong advocates of the smart use of data analytics. These tools provide huge benefits to our clients in litigation and investigations. H5MA is one such valuable tool that we regularly employ.